Deploy Smarter
Scale Effortlessly
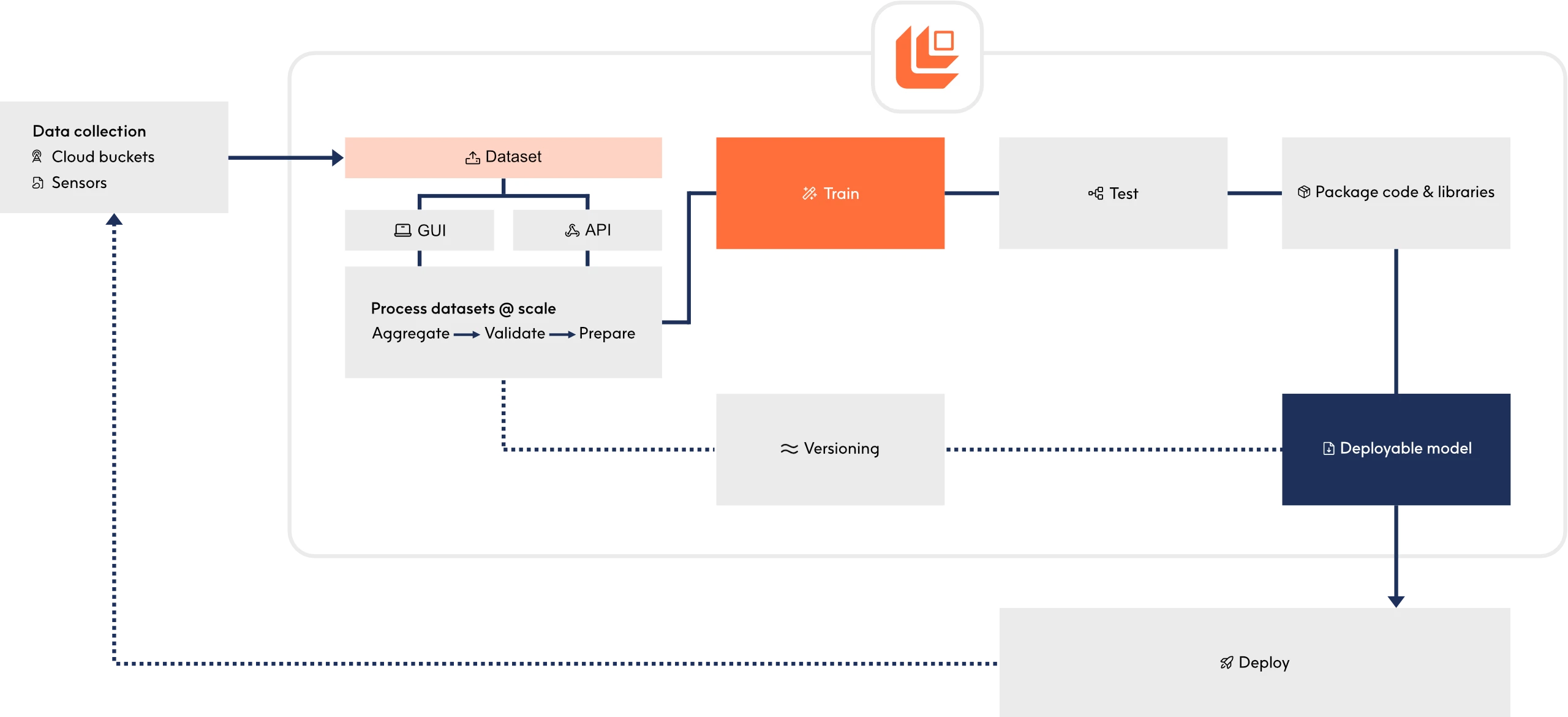
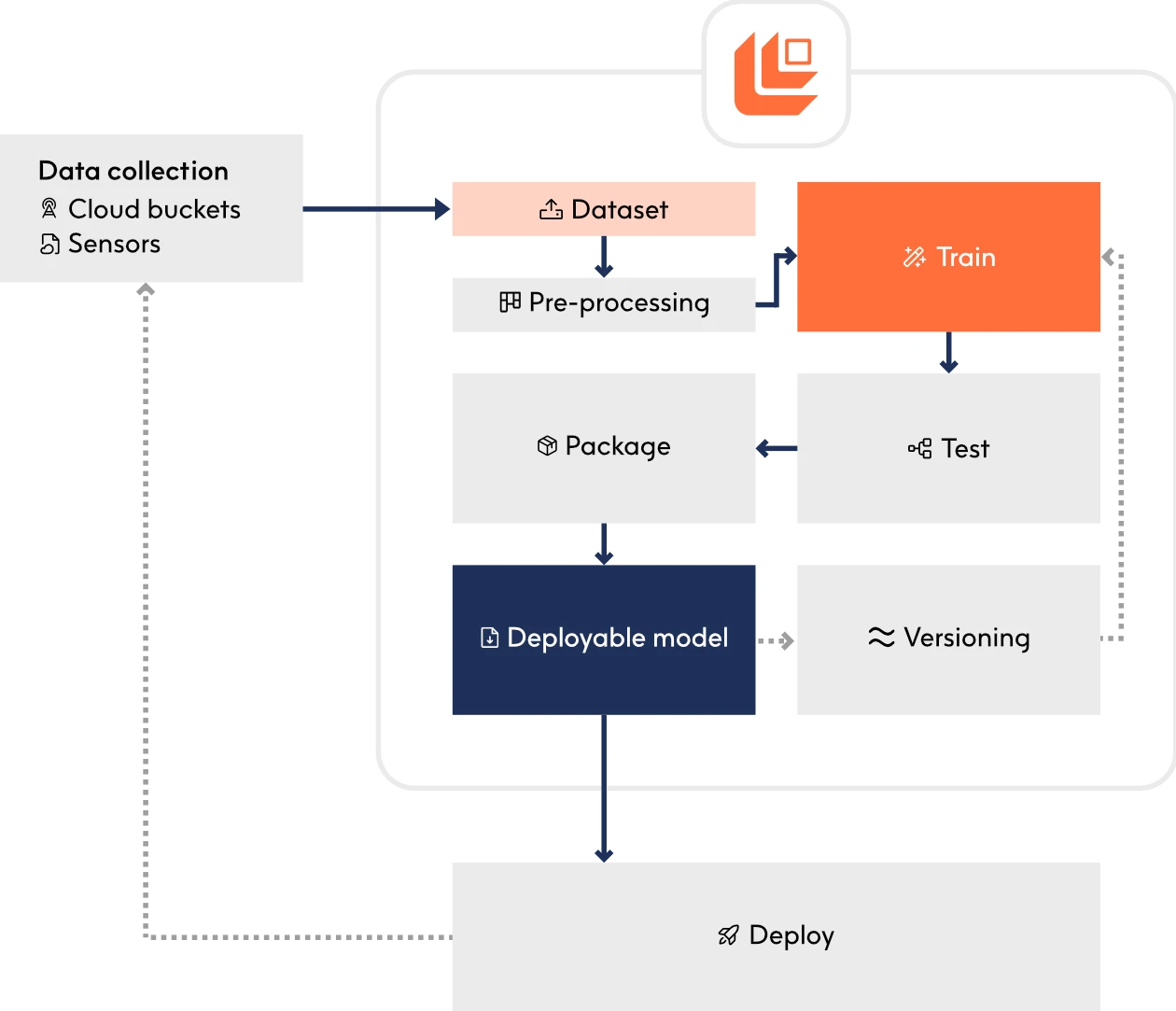
Logic-based AI models are designed to deploy seamlessly. They’re not just optimised—they’re engineered to fit their deployment environment perfectly. From automated optimisation to real-hardware benchmarking, every step of our deployment pipeline ensures that you’re deploying AI that performs as fast, efficient, and as cost-effective as possible.
Every model finds its sweet spot, balancing inference speed, energy consumption, and hardware constraints for peak efficiency. No wasted compute, no excess power draw.
Automated translation
Models are automatically converted into optimised low-level code, tailored to the target DSPs, edge, or cloud platforms—ensuring the lowest possible inference latency and energy consumption.
Deployment sweet spot
Logic-based models are rigorously profiled against hardware and deployment constraints to determine the ideal balance of speed, power, and resource efficiency—ensuring every deployment hits peak performance.
Edge to cloud scalability
Deploy on hardware as small as an MCU while scaling effortlessly to server-grade environments. Logical AI adapts to fit, from microcontrollers to high-performance DSPs.
Retrain and redeploy
Update models without full recompilation. Model parameters can be retrained and your system can deploy them in smaller, optimised packages, reducing update complexity on edge devices.
Validated benchmarks
Predictive performance, inference speed, and power efficiency are tested on real hardware through an automated, remote validation process.
Versioning
Track model performance over time, detect drift, and trigger retraining when beneficial—ensuring AI performs accurately, efficiently, and is continuously meeting your use case’s needs.