Frequently asked questions
How do I train an AI model using Literal Labs? 
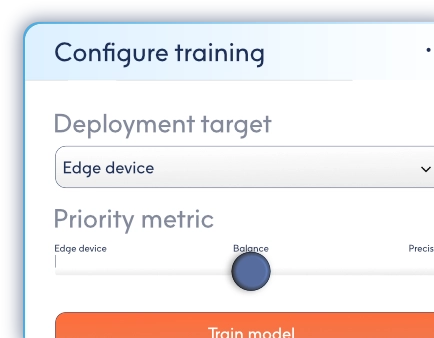
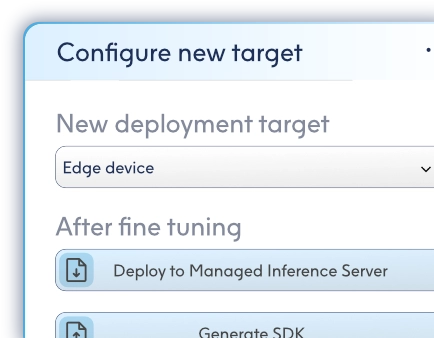
Training LBN models with Literal Labs is designed to be straightforward. Upload your dataset to the platform via the browser-based interface or API, configure a small number of training options, and start training. The platform handles data preparation, model training, benchmarking, and optimisation automatically. Once complete, your trained model is ready for deployment to your chosen environment.
What types of use cases does the platform support today?
It's currently focussed on industrial and operational AI use cases, including anomaly detection, predictive maintenance, time-series forecasting, sensor analytics, and decision intelligence. These are problems where reliability, efficiency, and explainability matter as much as raw accuracy. Support continues to expand as new model types and capabilities are released.
Do I need AI or data science expertise to use the platform?
No. The platform is built to be usable by teams without dedicated AI or data science specialists. Most workflows can be completed through the guided web interface with minimal configuration. For engineering teams that want deeper control, the API provides advanced options and tighter integration, but this is entirely optional.
Do I need GPUs or specialised hardware to use it?
No. Model training is handled by Literal Labs' managed infrastructure, and trained models do not require GPUs or accelerators to run. Models produced by the platform are designed to operate efficiently on standard CPUs, microcontrollers, and edge devices, as well as on servers.
What infrastructure do I need to get started?
Very little. To begin, you only need a supported dataset and a web browser. There is no requirement to provision training infrastructure, manage clusters, or install complex toolchains. Deployment targets can range from embedded devices to cloud servers, depending on your use case.
How does Literal Labs differ from traditional ML platforms?
Traditional ML platforms are built around large, numerically intensive models that demand specialised hardware and complex operational pipelines. Literal Labs takes a different approach, producing compact, efficient models optimised for real-world deployment. The result is faster training, simpler deployment, lower energy consumption, and models that are easier to understand and maintain.
How do I get access, pricing, or start a pilot?
You can request access or discuss pricing directly by contacting us. The team offers guided pilots for companies that want to evaluate the platform on real data and real deployment targets. This allows you to assess performance, integration effort, and business value before committing further.